Optimising Data Pipelines for Cryptocurrency Analysis: Airflow, Kafka, MongoDB
Table of Contents
- Project Diagram
- Setting Up the Environment
- Data Acquisition
- MongoDB: The Database Choice
- Kafka: Streamlining Data Flow
- Airflow: Automating ETL Processes
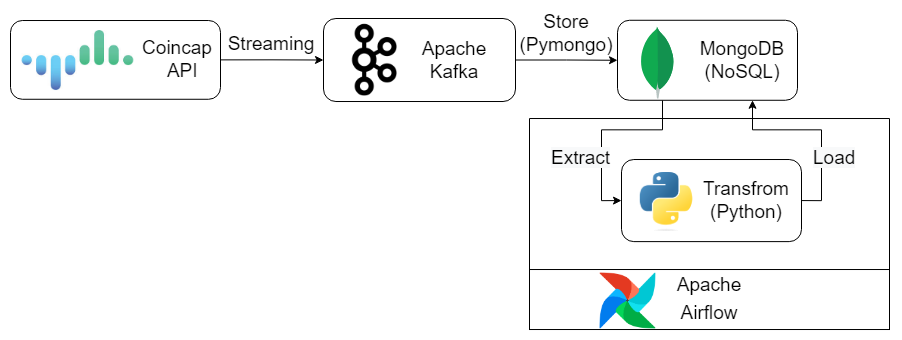
Project Diagram
Setting Up the Environment
Ubuntu 20.04 (WSL2) alongside Python 3.8 for our setup.
Data Acquisition
 Source: CoinCap
Source: CoinCap
We leverage the CoinCap API (coincap_api) to fetch real-time Bitcoin price data.
MongoDB: The Database Choice
MongoDB, a NoSQL database, is preferred for its ability to handle high-velocity and voluminous data efficiently, making it suitable for big data applications. Unlike traditional relational databases, MongoDB supports unstructured data and is schema-free.
 Source: MongoDB
Source: MongoDB
A comparison between relational databases and MongoDB:
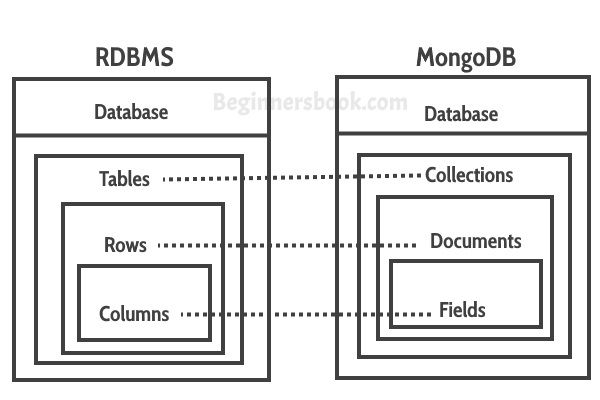 Source: RDBMS_MongoDB
Source: RDBMS_MongoDB
In MongoDB, data is stored in BSON (Binary JSON) format, and “_id” is an object, not a string. For seamless data extraction, conversion to a string is advisable.
Studio3T (https://studio3t.com/), a free MongoDB GUI, can be used for database connectivity.
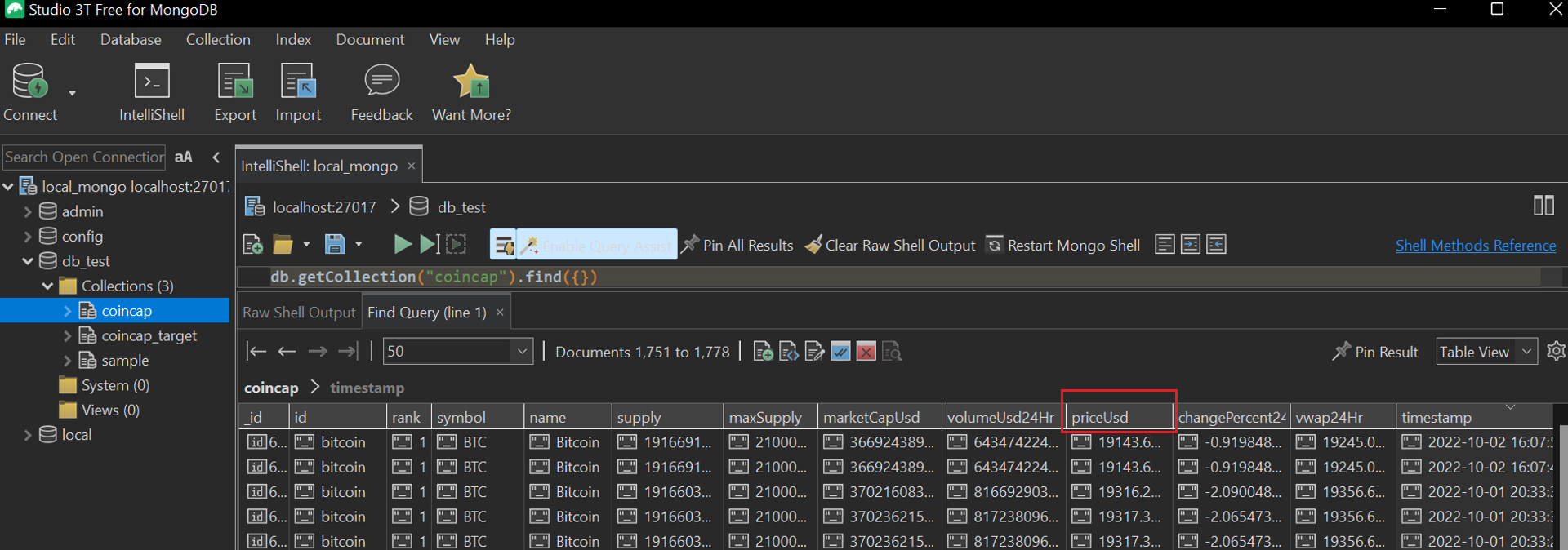
Python Integration with MongoDB
import pymongo
import pandas as pd
client = pymongo.MongoClient('localhost', 27017)
database = client["db_test"] # Database Name
collection = database["coincap"] # Collection Name
# Fetch data from MongoDB to Pandas DataFrame
query = {}
records = pd.DataFrame(list(collection.find(query)))
# Insert data into MongoDB
df = pd.DataFrame({'price': ['12.4', '1.4', '2.6']})
records = df.to_dict('records')
collection.insert_many(records)
Kafka: Streamlining Data Flow
Apache Kafka, an eminent open-source distributed event streaming platform, is utilised for managing real-time data streams. Its application helps circumvent potential bottlenecks associated with direct data storage in databases.
 Source: Kafka
Source: Kafka
The implementation involves three key steps:
- Publishing and subscribing to event streams, including data import/export.
- Storing event streams durably.
- Processing events as they occur or retrospectively.
Start Zookeeper and Kafka services:
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
Create a new Kafka topic:
bin/kafka-topics.sh --create --topic test-topic --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1
- Producers: Applications that publish events to Kafka.
- Consumers: Applications that subscribe to and process these events.
# producer.py
from kafka import KafkaProducer
import requests
import json
from datetime import datetime
brokers, topic = "localhost:9092", "coincap"
producer = KafkaProducer(bootstrap_servers=[brokers])
url = "https://api.coincap.io/v2/assets/bitcoin"
while True:
response = requests.get(url)
value = json.dumps(response.json()).encode()
key = datetime.now().strftime("%Y-%m-%d %H:%M:%S:%f").encode()
producer.send(topic, key=key, value=value)
# time.sleep(5)
The consumer section receives data and stores it in MongoDB:
# consumer.py
from kafka import KafkaConsumer
import pymongo
import json
brokers, topic = "localhost:9092", "coincap"
consumer = KafkaConsumer(topic, bootstrap_servers=[brokers])
client = pymongo.MongoClient("localhost", 27017)
database = client["db_test"] # Database Name
collection = database["coincap"] # Collection Name
for msg in consumer:
dict_data = json.loads(msg.value)
dict_data["data"]["timestamp"] = msg.key.decode()
collection.insert_many([dict_data["data"]])
Airflow: Automating ETL Processes
Apache Airflow is a powerful tool for authoring, scheduling, and monitoring workflows. Our use case involves automating the conversion of Bitcoin prices from USD to GBP, followed by database storage.
Set up the connection to MongoDB via the Airflow Web UI:
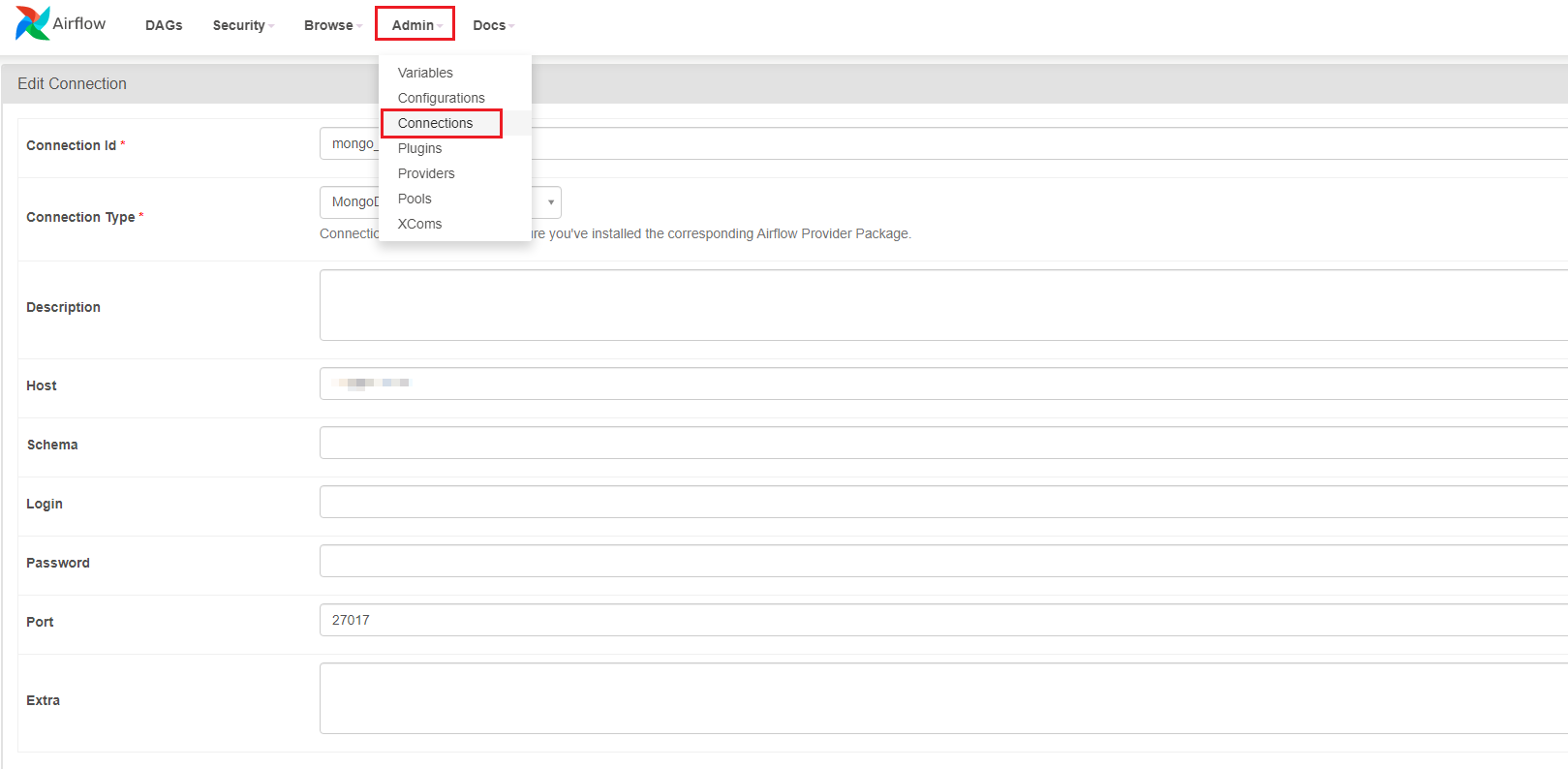
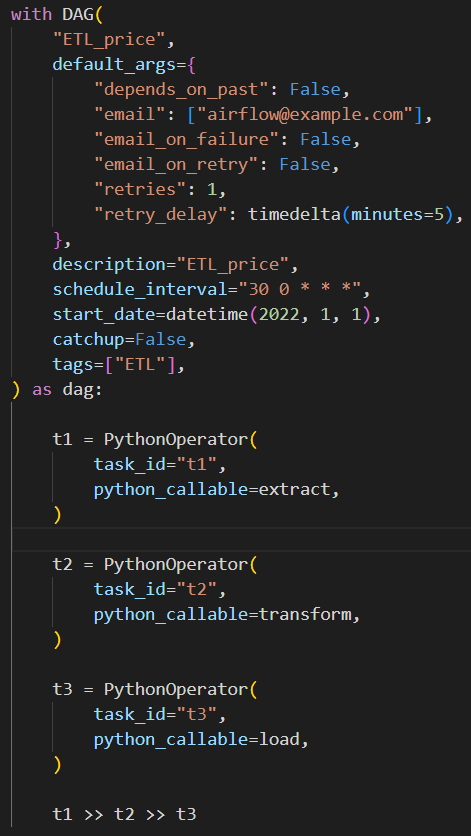
Define ETL tasks in the DAG:
- Extract: Fetch data from the source.
- Transform: Convert USD prices to GBP.
- Load: Store the transformed data in MongoDB.
These tasks are scheduled to run sequentially at 00:30 daily. Use crontab.guru for setting the schedule_interval.
- dags/dag.py
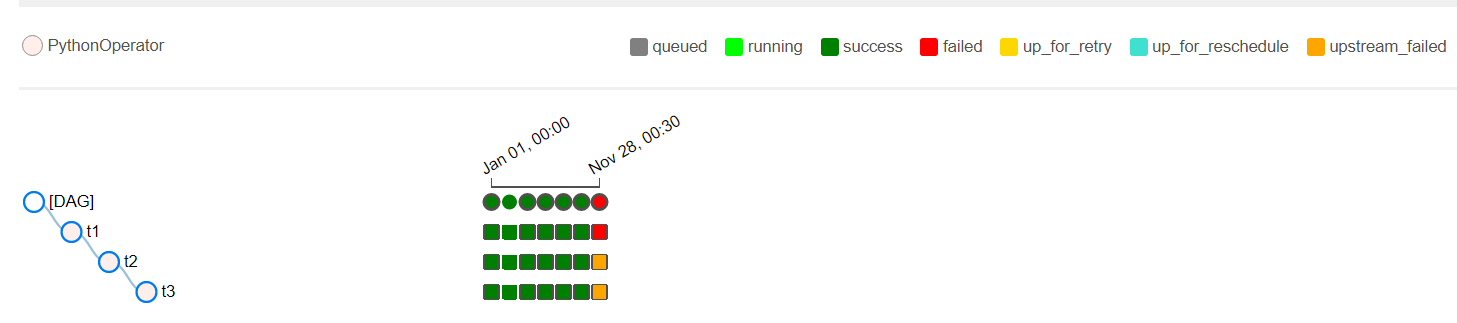
Task Sequence: task1 -> task2 -> task3
Log:
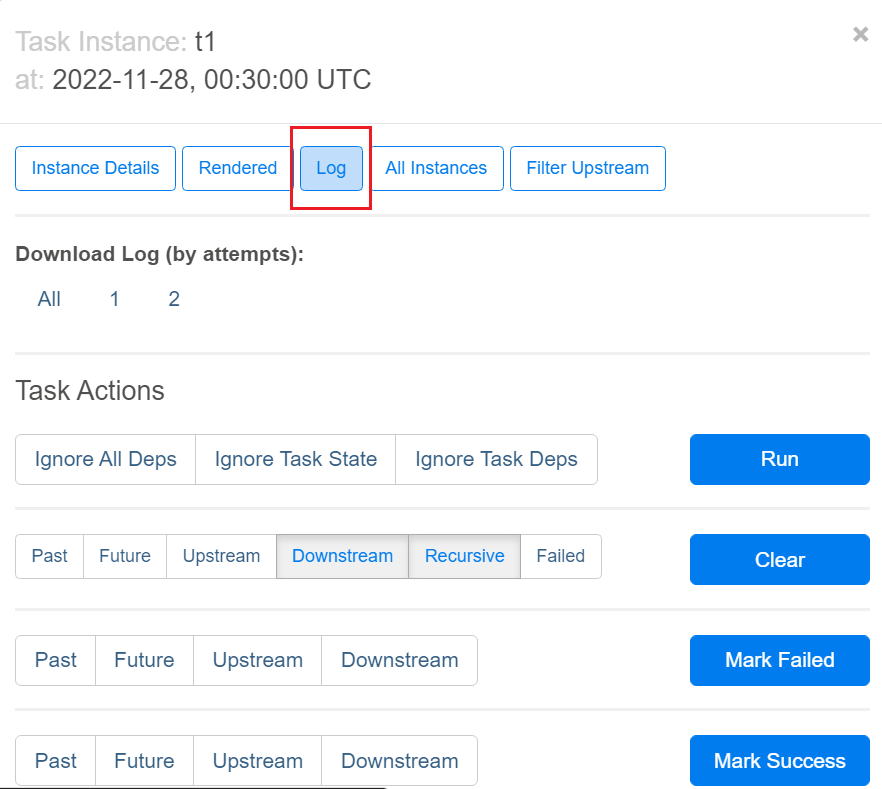
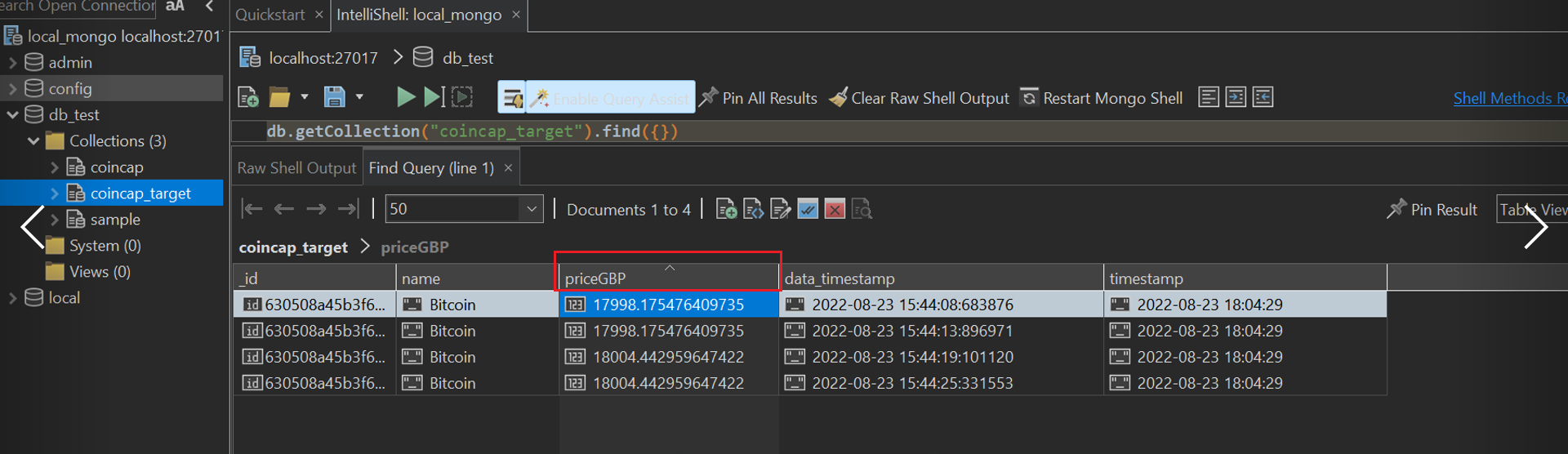
Result: