Analytics Engineering (dbt + BigQuery + Data Studio)
When it comes to working with data, many challenges arise. One of the biggest challenges is building a reliable and scalable data pipeline that can handle large volumes of data while ensuring the data’s accuracy and consistency. With dbt, you can transform, test, and document your data in a reproducible and scalable way. In this article, I’ll introduce dbt and show you how to utilise it with BigQuery.
Project Diagram
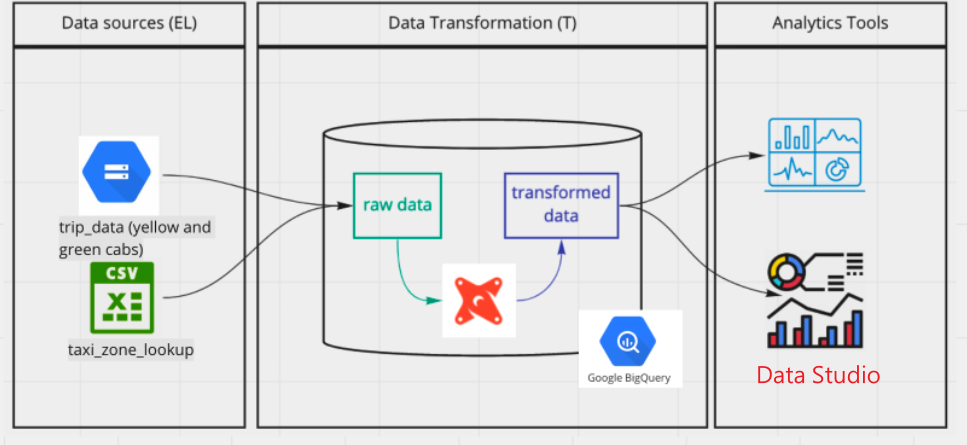 Source: DE_zoomcamp
Source: DE_zoomcamp
Challenges
In the past, data engineering and analytics were distinct fields with unique tools, languages, and skill sets. Data pipelines that are operated on platforms like Apache Spark or Amazon Redshift are orchestrated by data engineers using tools like Apache Airflow or AWS Glue. To query and alter data that is stored in databases or data warehouses, data analysts utilise technologies like Python or SQL.
However, this separation has some drawbacks:
- It separates data teams into silos, which makes it difficult for them to collaborate and align.
- Managing numerous tools and platforms adds complexity and overhead.
- It reduces agility and speed in delivering data products and insights.
To address these challenges, a new paradigm has emerged: Analytics Engineering.
Analytics engineering applies software engineering principles and techniques to data transformation and analysis. Analytics engineering aims to bridge the gap between data engineering and analytics by enabling data teams to work directly within the data warehouse using a single tool: dbt.
What is dbt (data build tool)?
 Source: dbt
Source: dbt
dbt is an open-source command-line tool that enables data analysts and engineers to transform raw data into valuable insights. It assists users in managing their entire data pipeline, from extracting data from sources to transforming and loading it into a target data warehouse. With dbt, users can build, test, and deploy data pipelines as code, making it easier to maintain and scale their data infrastructure.
dbt is designed to work with SQL-based data warehouses, such as BigQuery, Redshift, Snowflake, and others. It uses a declarative syntax to define data transformations, making it easy for non-technical stakeholders to understand what the data is doing. dbt also has a testing framework that enables users to ensure data quality and consistency throughout the pipeline.
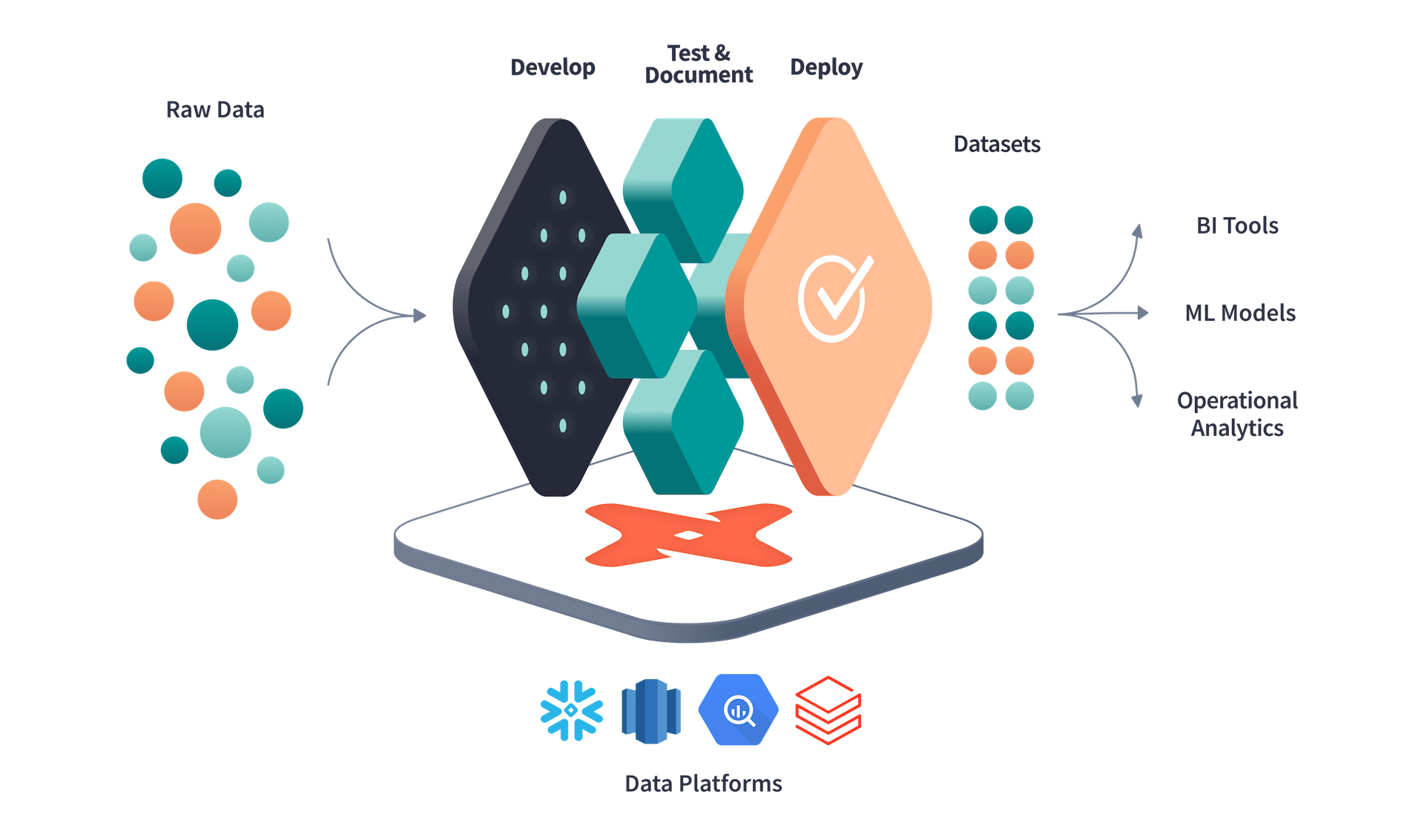 Source: dbt
Source: dbt
What are the features of dbt?
Modularity: dbt allows you to break down your data pipeline into smaller, reusable components, which can make it easier to maintain and scale over time.
Versioning: dbt uses Git to manage versions of your code, which makes it easy to track changes and collaborate with others.
Testing: dbt provides a testing framework that allows you to test your data pipeline at different stages of the pipeline, ensuring the accuracy and consistency of your data.
Documentation: Documentation is generated automatically from our models, sources,and tests using Markdown syntax. Documentation provides metadata such as descriptions, tags, columns types, etc.,as well as lineage diagrams that show how datasets depend on each other.
Seeds: Seeds are CSV files that contain static or reference data such as lookup tables or configuration parameters. Seeds allow us to load small amounts of data into the warehouse without using external sources.
Packages: Packages are collections of models,sources,tests,macros etc.,that can be shared across projects or with the community via GitHub or other platforms. Packages allow us to leverage existing code or best practices from other users or organizations.
Using dbt Cloud
dbt Cloud is a web-based application that helps data teams configure, deploy, and control dbt project. dbt Cloud leverages the power of dbt Core and adds features such as:
Integrated development environment (IDE): A web-based interface that allows you to write, test, and run dbt models with syntax highlighting, autocomplete, error checking, and version control integration.
Scheduling: A feature that lets you schedule dbt jobs to run automatically at specified intervals or triggers. You can also monitor the status of your jobs and get alerts for failures or anomalies.
Documentation: A feature that generates interactive documentation for your dbt project based on your code comments and metadata. You can explore your data models, view lineage graphs, query results, tests, sources.
Monitoring & alerting: A feature that helps you track the performance and quality of your data models with metrics such as run duration, freshness, row count, test results etc.
Get started with dbt cloud
First, we must create a dbt cloud account and set up the project by connecting to my data warehouse(BigQuery) and Github. Then, click “initialize your project” on dbt Cloud Here, we’ll be able to configure your project settings(dbt_project.yml).
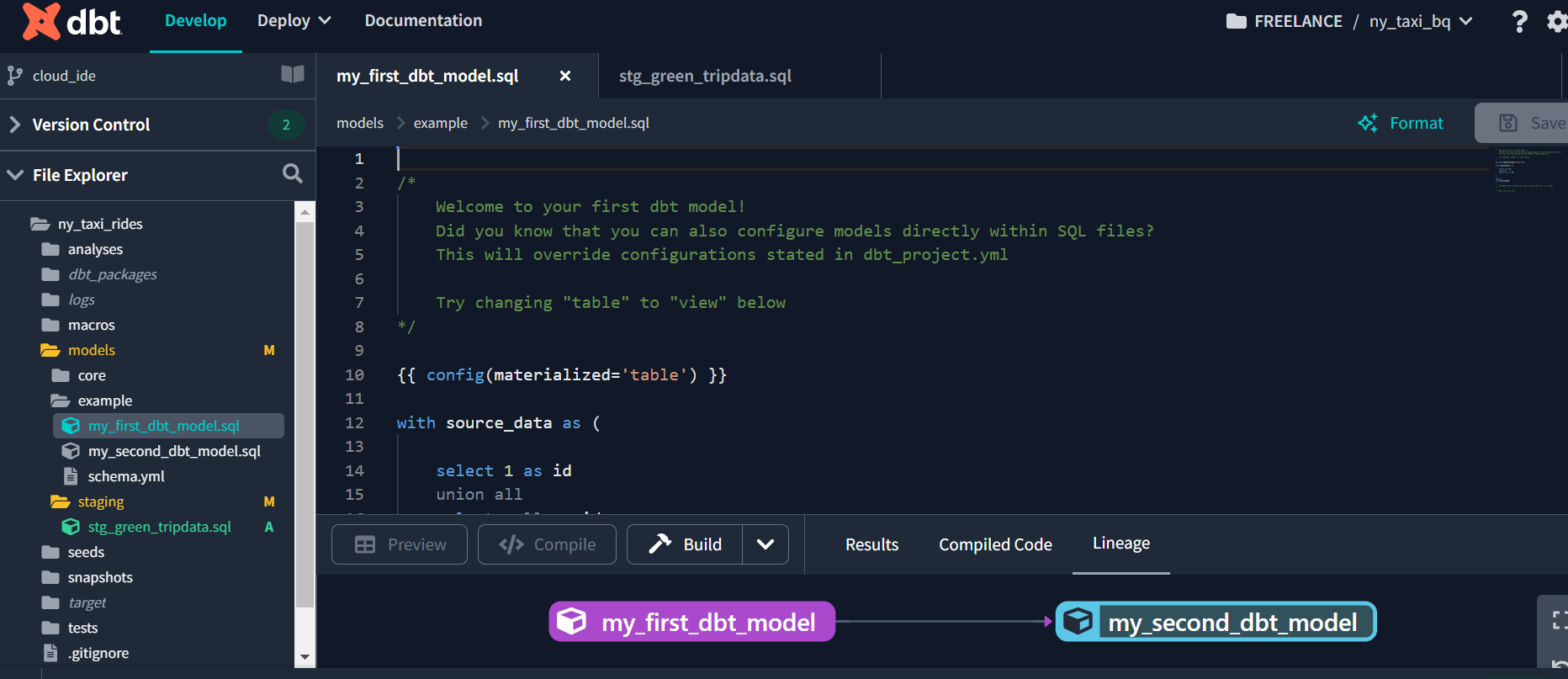
Once you’ve set up your project settings, you can build and deploy your data pipeline using dbt Cloud. We’ll need to create a series of data models in your dbt project to do this.
To create a new data model, simply create a new SQL file in your dbt project directory and define your data model using SQL. You can also define your data model using YAML files, which define the dependencies between your models.
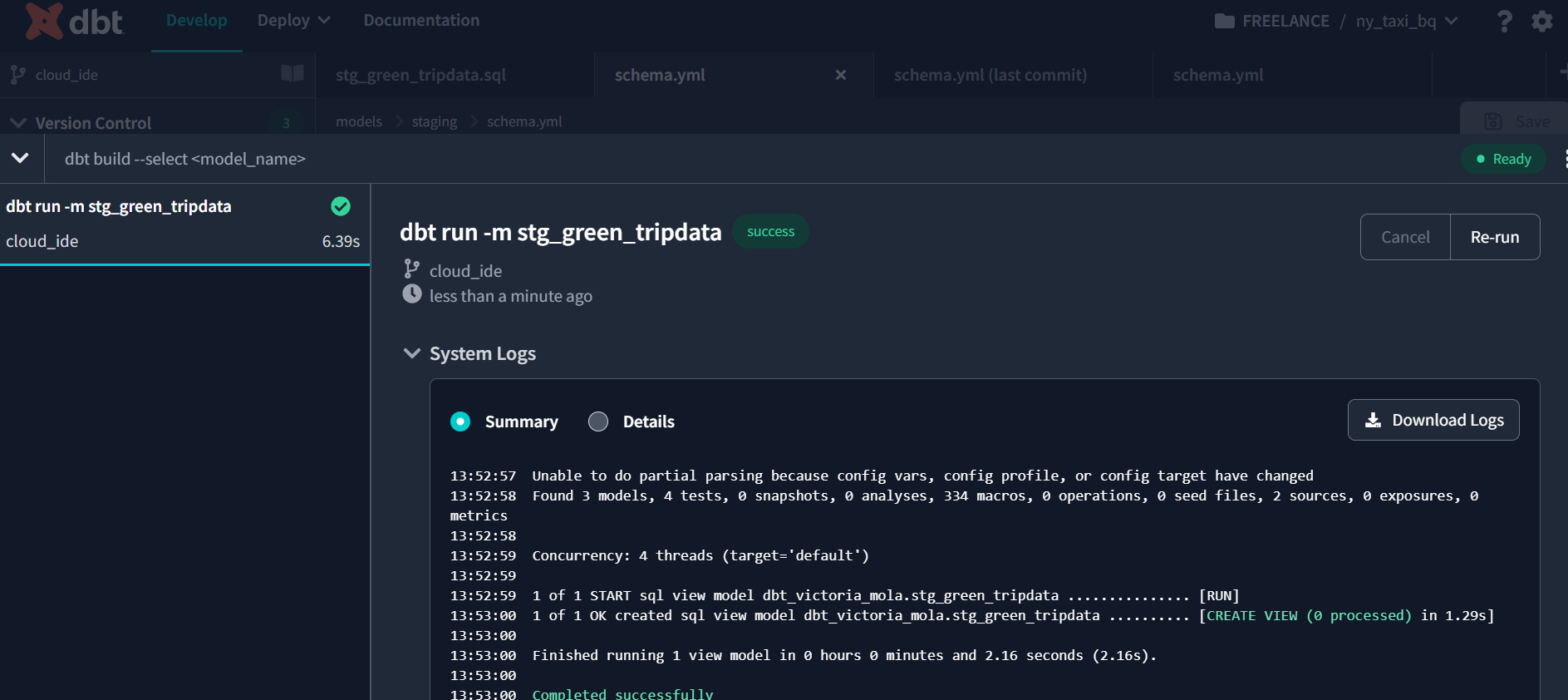
Once you’ve defined your data models, you can use command dbt run to compile your data models into SQL queries and applies any transformations to your data. It checks for any changes in your source data and creates the final output. Essentially, it runs your data pipeline end-to-end.
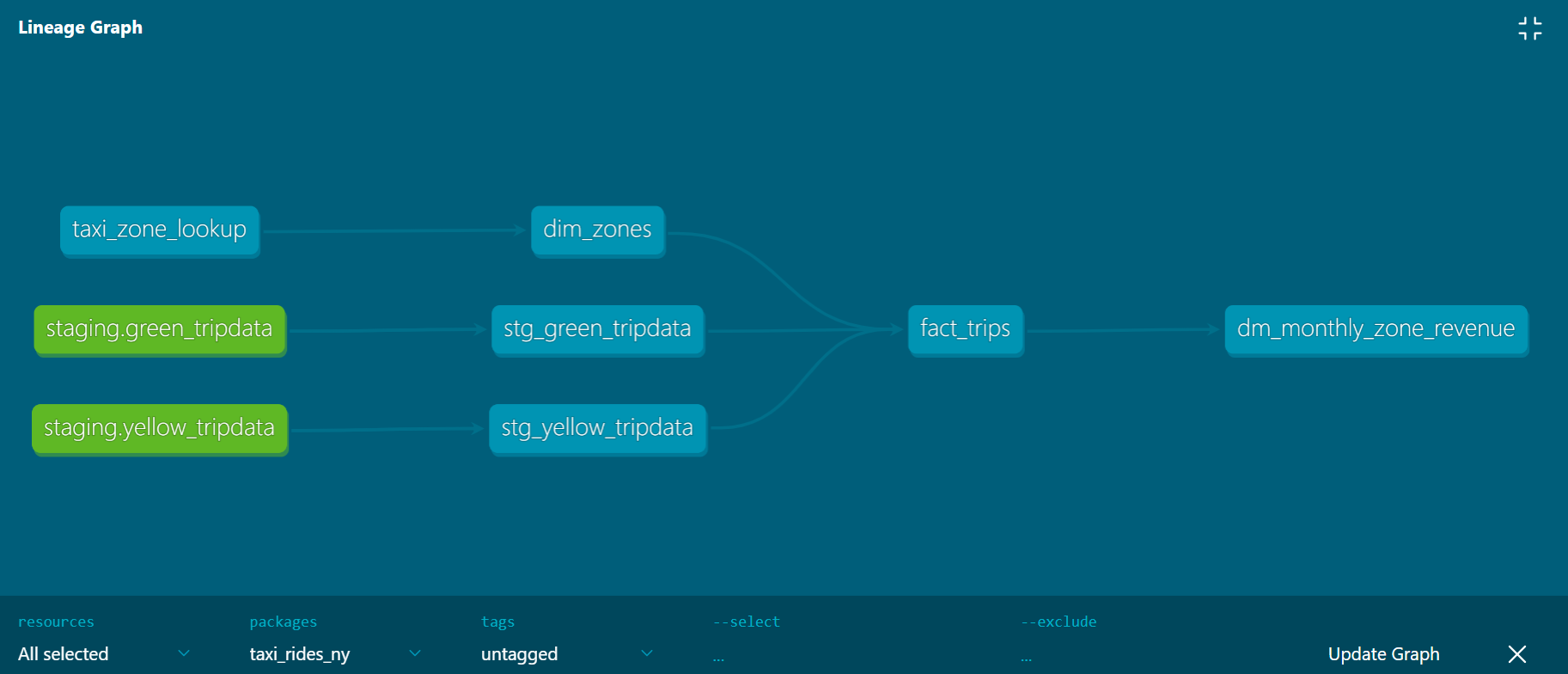
dbt lineage graph is a visual representation of the dependencies and relationships between data sources, models, and outputs in a dbt project1. It is based on the concept of a directed acyclic graph (DAG), which is a way of modeling data transformations as a series of nodes and edges1. A dbt lineage graph can help you understand how your data flows from raw sources to final reports, identify potential issues or inefficiencies in your project structure, and document your data pipeline for other stakeholders.
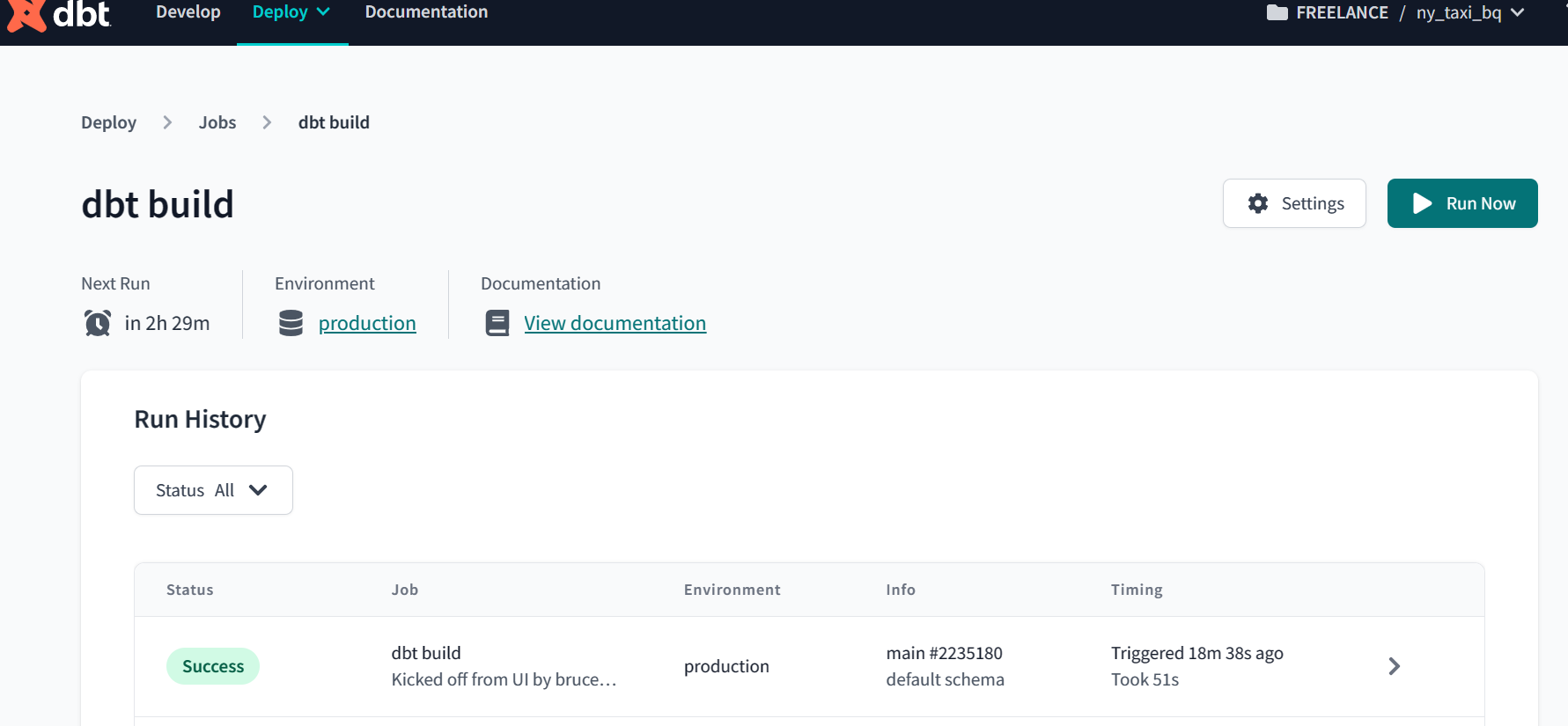
Deployment
To deploy your dbt project using dbt cloud, we need to follow these steps
- Create a deployment environment by selecting “Deploy” and then “Environments”. Name your environment, add a target dataset, and select an account type.
- Schedule a job by selecting “Deploy” and then “Jobs”. Name your job, select an environment, choose a run frequency, and add any custom commands or notifications.
- Deploy your project by clicking on the “Deploy” button in the dbt cloud UI. You can also trigger a manual run by clicking on the “Run” button.
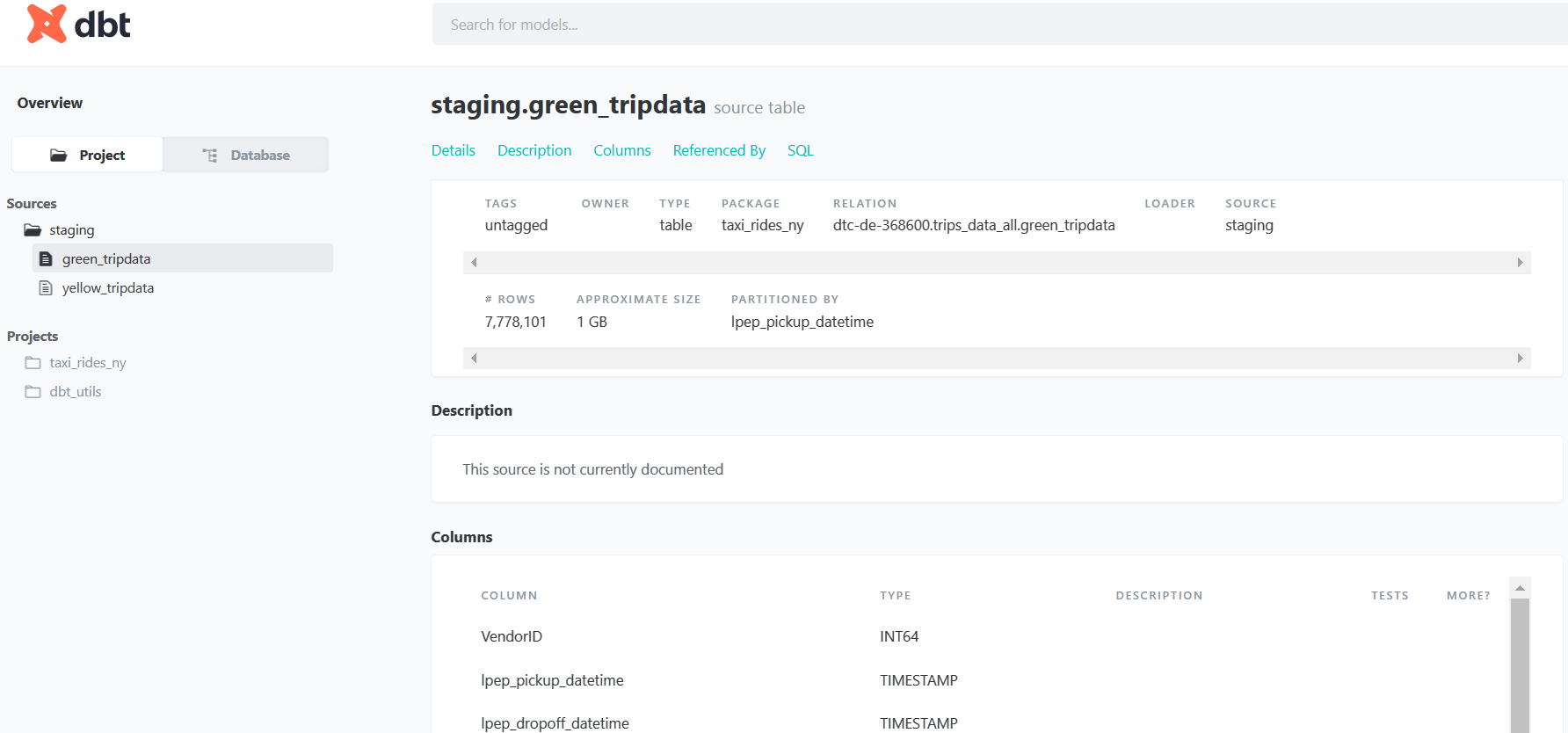
Here we can see the document:
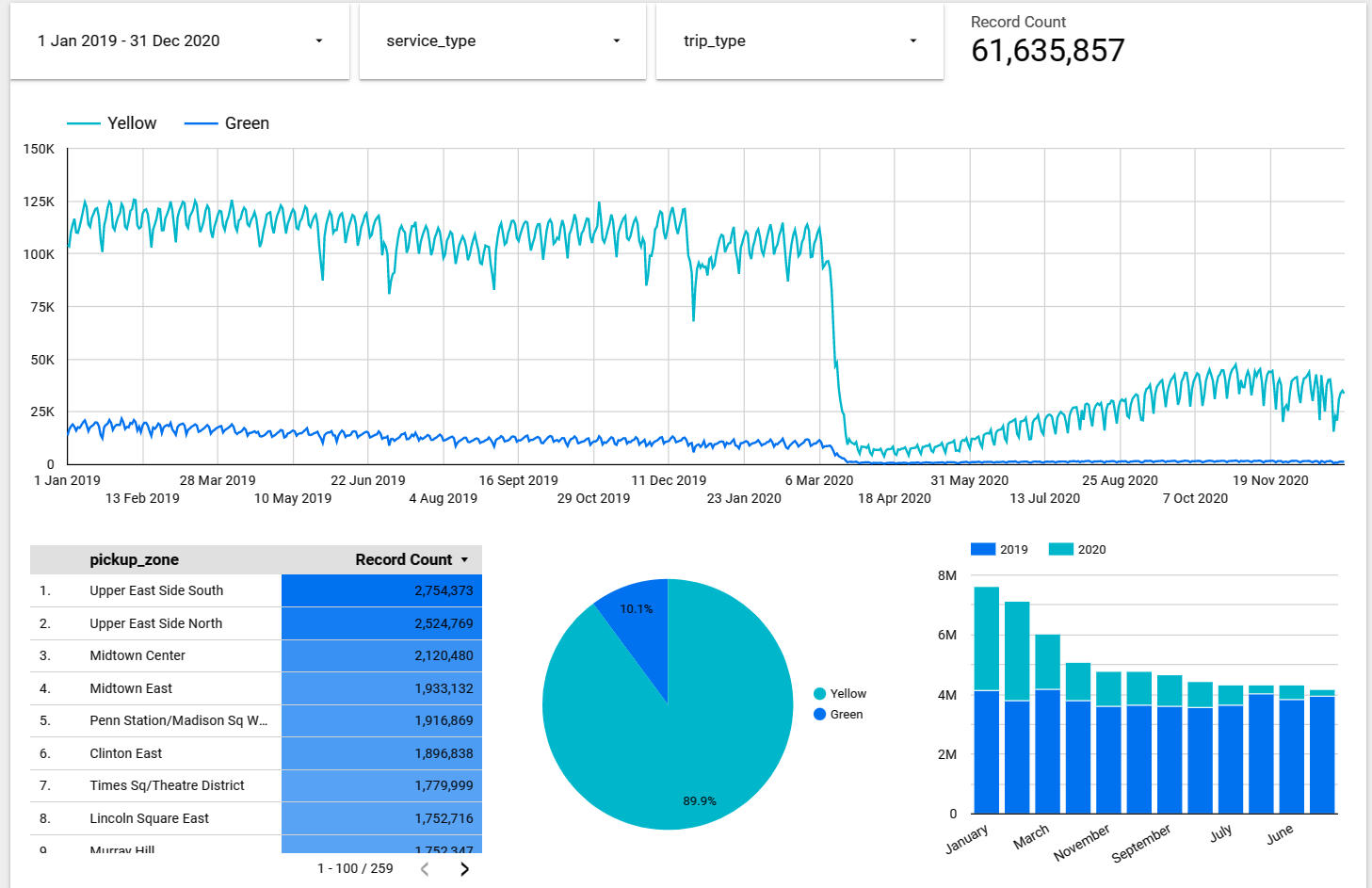
Data studio
Finally, we can use Google Data Studio to connect BigQuery and present the transformed data through the dashboard.
Conclusion
dbt is a powerful tool that helps data teams manage complex data pipelines more efficiently. By offering a user-friendly online interface, automated deployment tools, and enterprise-level security features, dbt Cloud expands the capability of dbt. With dbt and dbt Cloud, data teams can collaborate more effectively, deploy changes faster, and ensure data quality with confidence. If you are looking for a fast and reliable way to transform your data warehouse using SQL, then you should give dbt Cloud a try. It will help you streamline your workflow, improve collaboration,and deliver trusted insights faster.